Density Function Design
In this article, we'll present some practical design guidelines and rationales behind density functions. Density functions play an important role in our terrain generation and carefully designing such functions is rewarded with "well-behaving" terrain.
The importance of being linear
Our underlying type of functions can be specified as $$f: \mathbb{R}^3 \to \mathbb{R}~$$ with the terrain surface being defined by $$f(x, y, z) = 0$$. In this unrestricted appearance, this type of function is usually called "density function" and can be interpreted as a material "density" that is positive for the material and negative for air. (We usually define it the other way round, i.e. negative values being inside, as this correlates better to the following definition. Both interpretations are equivalent.)
Allowing arbitrary density functions is potentially risky as there is nearly no further information that we can assume about the values. For all we know, they could be clamped to $$1000~$$ right under the surface while all air values are randomly between $$-1~$$ and $$-2$$. It is therefore beneficial to further restrict the type of functions that we use. One especially popular sub-category of density functions are signed distance functions (SDFs). An SDF is a normal density function with an additional semantic interpretation of the function values: $$f(x,y,z)~$$ is the (signed) euclidean distance of $$(x,y,z)~$$ to the surface. The "signed" just means that if $$(x,y,z)~$$ lies inside the terrain then the value of $$f~$$ is the negative distance to the surface and the positive one if the point lies outside.
What do we gain from this restriction?
In most implementations of Marching Cubes, we do not actually search for the terrain surface. We just evaluate the density function at all grid points and for every sign change along an edge, we linearly interpolate the two density values to obtain an estimate of the surface location. This interpolation assumes that the function behaves like an SDF. If the function values are (a multiple of) the distance to the surface, than this interpolation yields pretty accurate results. However, in the case of arbitrary density functions, the results can be dramatically wrong.
The following images show the effect of linear interpolation (red line) for different types of functions (green line). The saved densities ($$d_0~$$ and $$d_1$$) are the same for all cases and therefore the estimated surface position $$x'~$$ is also the same. However, the actual surface position $$\hat{x}~$$ may be hit correctly - or just plainly wrong.
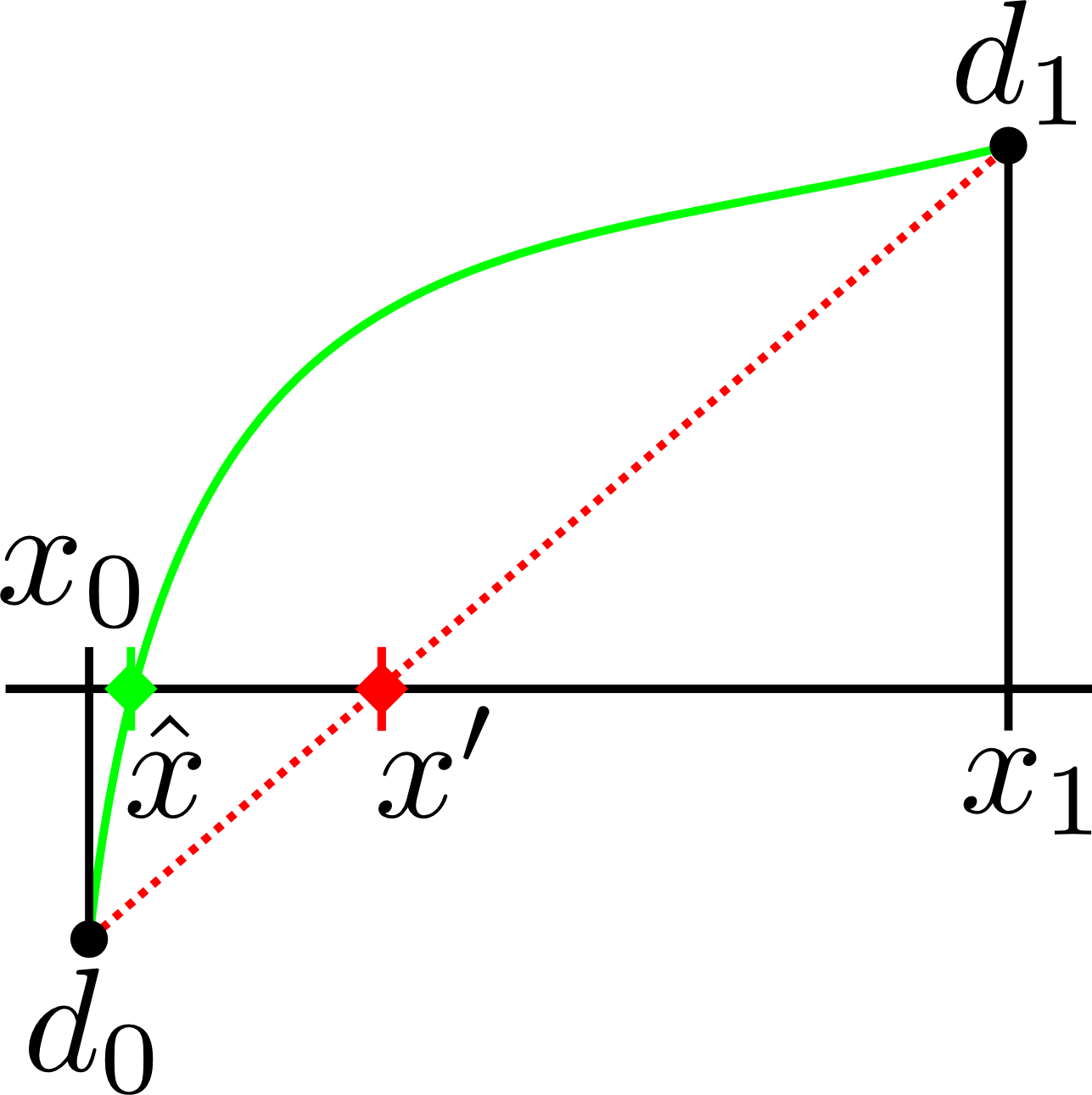
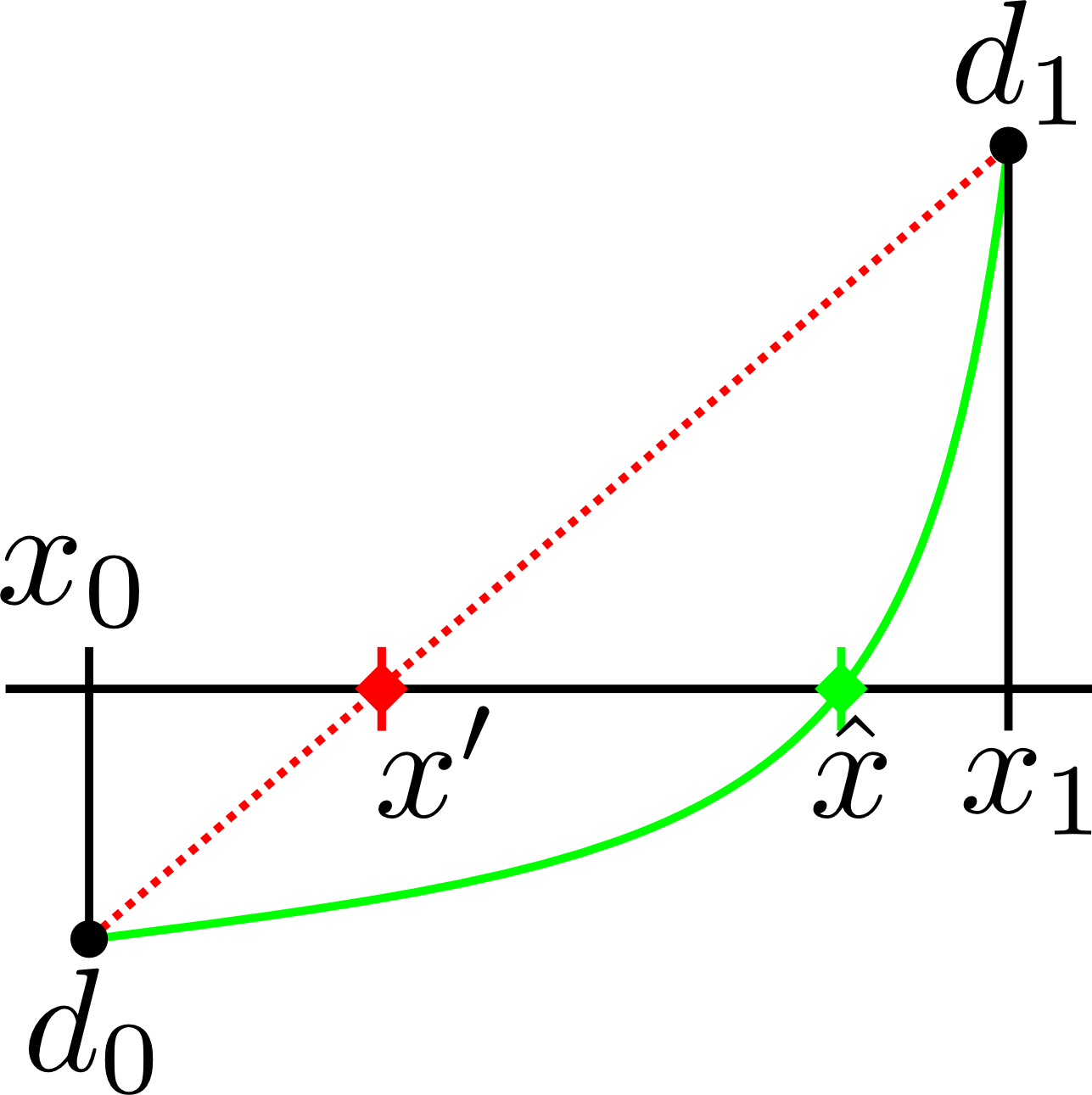
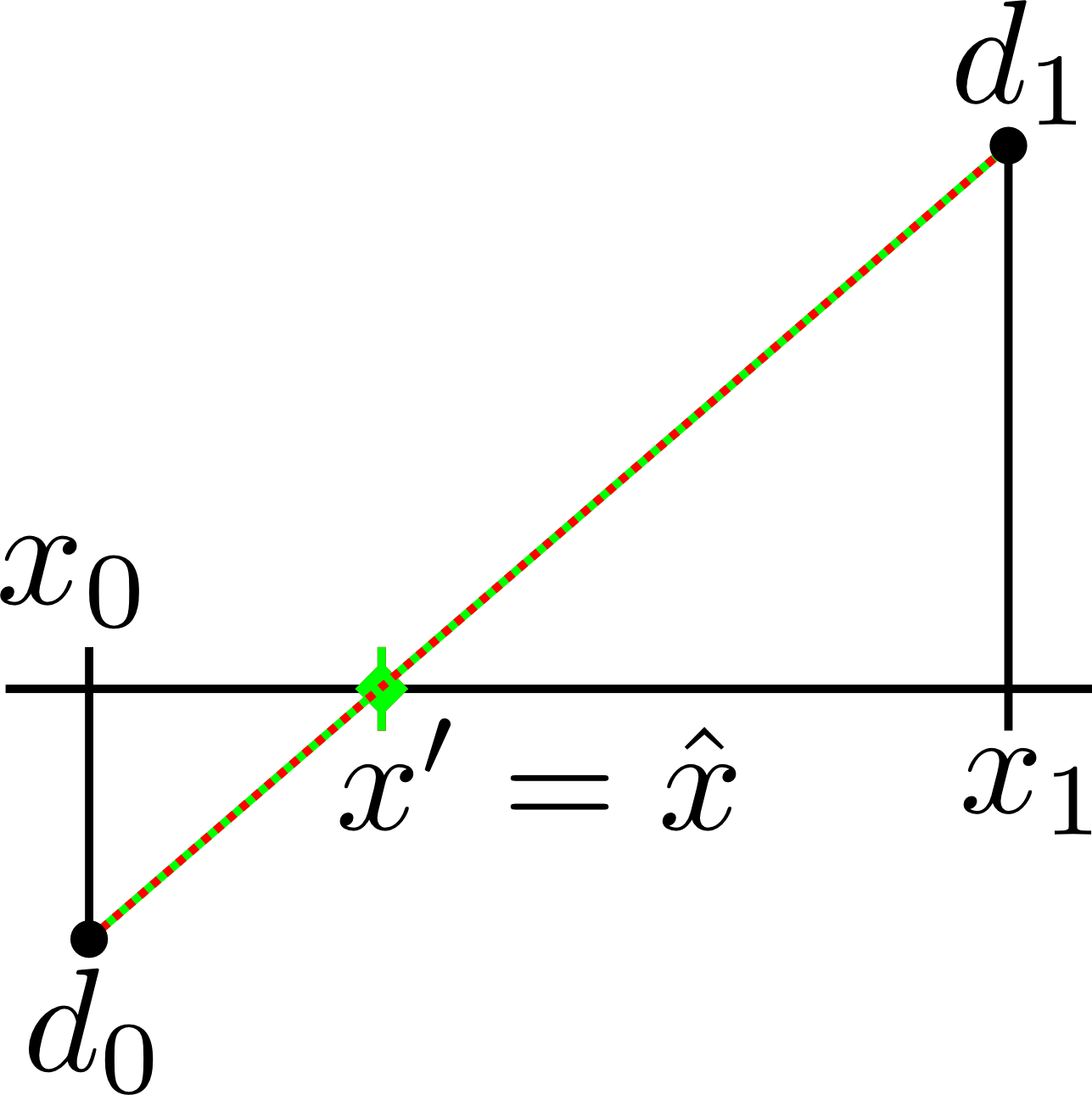
So for example, if you have to design a sphere with radius $$r~$$ and center $$c$$, you may come up with the "normal" definition $$\| (x,y,z) - c \| - r$$, which is negative inside the sphere and positive outside of it. While implementing this, you may notice the "sqrt" that is involved in the calculation of the distance and quickly come up with the equivalent formula $$\| (x,y,z) - c \|^2 - r^2$$ that has the same isosurface but uses only multiplication and addition. However, this formula is not linear. A small example shows that the interpolation can now be faulty. If the center is the origin and we have a radius of 1.5, we would sample a value of $$1\cdot 1 - 1.5 \cdot 1.5 = -1.25~$$ at the position $$(1,0,0)~$$ and $$2\cdot 2 - 1.5 \cdot 1.5 = 1.75~$$ at $$(2,0,0)$$. We would expect the isosurface to be at $$(1.5,0,0)$$. However, linear interpolation between $$-1.25~$$ and $$1.75~$$ results in $$(1.4167,0,0)$$ being calculated for the isosurface intersection.
In theory, scaling a function with an arbitrary positive constant has no effect on the terrain quality (disregarding floating point arithmetic). However, my personal experience is that you are well advised to design all your density function to be "as SDF as possible", i.e. they should represent a signed distance to the surface. While it does not matter for single functions, it makes combining several density functions (e.g. via min/max) more intuitive as you do not have to care about different scales.
This section assumed that the terrain surface is found by linear interpolation rather than by search. If we use a normal binary search (or bisection) to find the surface, the type of function does not really matter as the speed of convergence does not depend on the function values. However, normal bisection tends to be slow and inaccurate. We can considerably increase the search performance by using linear interpolation (mathematically, we use the regula falsi method). As we are now using linear interpolation again, having SDF-like functions is beneficial (by increasing the speed of convergence).
To clamp or not to clamp
A popular question is "are density functions restricted to $$[-1,1]$$, or should they be?". From the above section it should be clear that this is neither a requirement nor is it advisable as it directly violates the "as SDF as possible" guideline. Nevertheless, there is some room to negotiate that depends on the storage representation.
In the case of Hermite Data (cf. Terrain Engine series), all density values are discarded after one layer of volume data is generated. It is therefore irrelevant if the data is clamped or not.
However, storing and operating on pure density data is still popular and in this case, clamping is a relevant option. Why do we even consider this if the section begins with a counter-argument? Keeping the whole density data SDF-like can be prohibitively expensive. The initial density (i.e. the terrain generation) may have this property but modifying the terrain introduces a problem. Changing the density function (i.e. digging out a sphere) is not a local operation anymore and all density values need to be updated. Why this is necessary may not be immediately apparent but becomes clear if we imagine digging down into a plane of stone. A simple plane starting at zero can be described by the SDF function $$f(x,y,z) = y$$. Suppose that we want to dig down a hundred units. Initially, all density values at this point are around $$-100~$$ as this is the signed distance to the surface. However, after digging half way down, those values should be around $$-50~$$ as the nearest surface is our $$50~$$ units deep tunnel. As the same argument holds for all values further down, modifying the terrain locally is suddenly a global operation. In most scenarios, this is prohibitively expensive.
What are our options in this case?
As the section title may suggest, clamping can be considered an option. Unfortunately, simple clamping is followed by a considerable quality degradation. The range to which we clamp the density values has to be chosen with care. If we clamp too early, the terrain may become jagged and less smooth (linearly clamping between clamped air and clamped material always results in the surface being located at the mid of the edge, assuming symmetric limits). To keep the function SDF-like as long as it is not clamped, terrain modifications need to be calculated until they are clamped. For example, a sphere with radius $$r~$$ and clamping limits of $$\pm c~$$ would require updating density values in a radius of $$r+c~$$ around the sphere center. Thus, we want to keep the clamping limits as low as possible while keeping the terrain quality high. As a rule of thumb: if one of the density values of a sign-changing edge is clamped, terrain quality suffers.
There is a quite different approach to modifying terrain densities than the usual min/max CSG operations. In this approach, keeping the densities SDF-like is not required as they do not represent distances anymore. If we interpret the densities as "terrain density" with positive values being terrain and negative being air (with $$-1~$$ interpreted as "full air"), we can modify the terrain by adding or subtracting "densities". While this approach abandons a lot of fine-control over the terrain shape, it is a lot easier to implement and cheaper to modify. It also works well with normal "digging" operations. The terrain density is reduced until it gets negative; hard stone has a high "density" while loose earth has a low one. Effectiveness of various tools against different materials can be modeled by the speed of density reduction.
My personal recommendation: use the Hermite Data representation whenever possible.
Analytic derivative vs. finite differences
In case we decide to store the volume as Hermite Data, the question arises how to calculate the normal or gradient at the isosurface intersection.
Assuming that we can evaluate our density function $$f(x,y,z)~$$ at arbitrary positions, a good guess for the gradient $$\nabla f~$$ can be made using finite differences, especially a central difference. This is quite straightforward as we can approximate $$\frac{\partial}{\partial x} f(x,y,z)~$$ by calculating: $$\frac{1}{h} \left( f(x+h,y,z) - f(x-h,y,z) \right)$$ for a sufficiently small $$h~$$.(Similarly for $$\partial y~$$ and $$\partial z$$). In the actual implementation we can easily drop the $$\frac{1}{h}~$$ as we usually normalize the gradient to get a sound normal. Finite differences can almost always be used as a fallback method to acquire a gradient of a density function. They require almost exactly six times the computational cost of a single density evaluation. (This can be lowered to four times at the cost of some precision if the central difference is replaced by a forward or backward one.)
The second and more precise way to calculate the gradient is actually deriving the density function in an analytic fashion. That is, if we have a way to calculate or evaluate $$\frac{\partial}{\partial x} f$$, $$\frac{\partial}{\partial y} f$$, and $$\frac{\partial}{\partial z} f$$, we are in the unique position to evaluate the exact gradient of $$f$$. Using our node/expression system, this is actually possible and will be presented in a later article by Marcus.
Performance profiling of our system suggests that evaluating finite differences and the analytic derivative have about the same computational cost. Thus, the question "why bother with the complex implementation of analytic derivative" arises. There are actual practical reasons beside the mathematical beauty of a real derivative. One of the main reasons that made us use Hermite Data was the presentability of sharp features like corners and edges. And it is exactly in their vicinity that the finite differences tend to produce high errors. An example of such can be seen in the following figures.
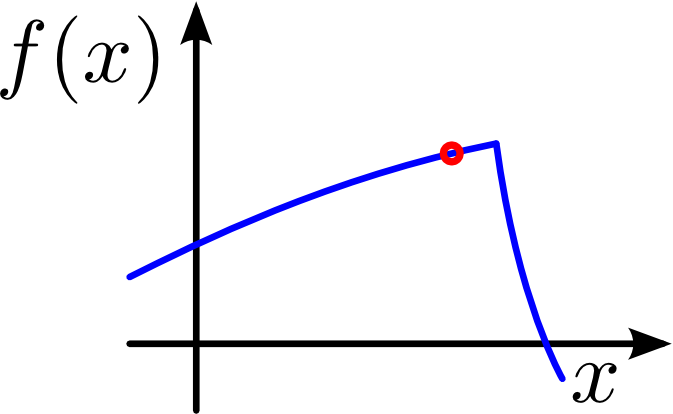
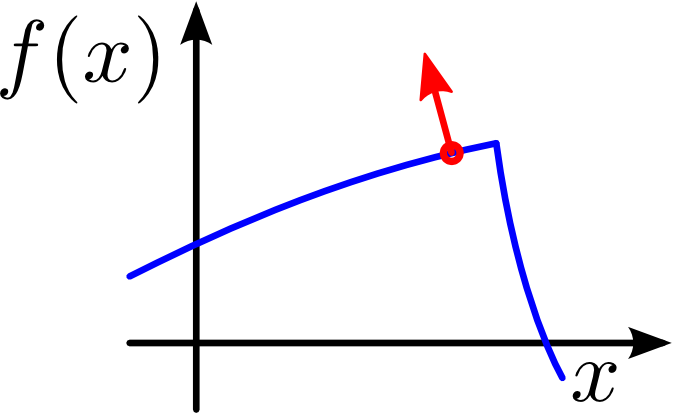
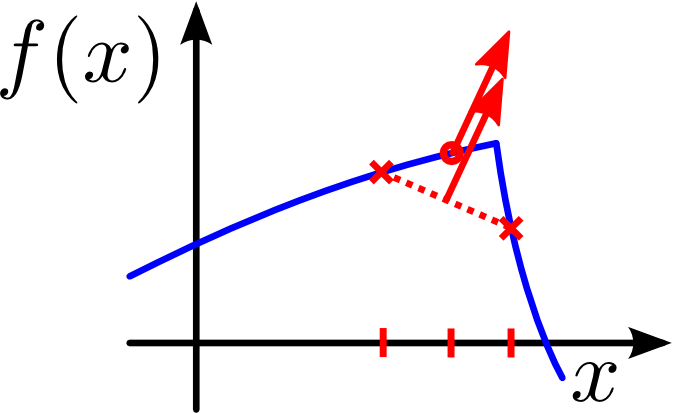
If the gradient of the (blue) function is to be evaluated near a sharp feature (red circle), analytic differentiation will produce correct results (middle figure) while finite differences (right figure) become faulty.
Summary
This article discussed some important properties of density functions. Understanding these properties aids in the creation of controllable and predictable terrain functions.
The first recommendation is to use density functions that are linear, i.e. they should represent a signed distance function as closely as possible. This is especially important if the densities are stored and future operations are executed on the density values. In the case of Hermite Data, SDFs are still advantageous but the error of non-SDFs can be reduced by using a search instead of plain interpolation.
In the event that you cannot use Hermite Data, clamping of density values becomes a valid option as local operations tend to have global impact if the values are not clamped. However, clamping tends to have messy implications as well, therefore my real advice here is to use Hermite Data.
The third section briefly justifies our efforts to implement analytic derivatives to calculate gradients as opposed to finite differences.