Node-based Evaluation Part 2 - Node Networks
First of all, to explain the long downtime between Part 1 and this: I prioritized actually working on the engine to writing these articles, and some problems came up that I did not foresee (as you can probably tell from the many "Marcus worked on JIT" in the Weekly Updates). Since most of these problems have been fixed by now, I expect to be able to churn out new articles more frequently.
Addendum to Part 1
Before we get into the core idea of the node network system, there is an addendum to the last post which I promised in the comment section. The Perlin noise I presented was a simple gradient noise, which's grid-based origin is clearly visible. Especially when thresholding at the 0 point, the resulting noise function does not look very good:

As I already implied in the last post, we can fix this by also generating a value noise (which simply assigns values to the grid points and uses the cubic interpolator to interpolate them):

Finally, we blend both of these noises and obtain:


Combining Noise functions
In this article, we will take a look at the node network system currently used in the Upvoid Engine. To understand why we developed it this way, we will first state the goals of our system, i.e., what we want to achieve with it. We took these goals and created a first version of our node system, but then noticed that a) it was not quite as good as we had hoped, and b) some new features we wanted to have did not work with our concept. So we scrapped it and created a new system, which is the system we ended up using.
As stated in the last paragraph of part 1, we have an interest in combining different noise functions into one. For illustration, we could consider a simple perlin noise function as this bit of C++ code:
float result = perlin(x,y,z);This is fine by itself, but we also want more complex transformations of the noise, such as:
float pX = x/50.0;
float pY = y/50.0;
float pZ = perlin(pX,pY,z);
float result = perlin(pX,pY,pZ);Ideally, we want a system to express this, for a multitude of reasons. We want to enable designers unfamiliar with noise functions to create their terrain with an easy-to-use GUI. At the same time, we want to retain the expressive power of a programming language, at least partially. Furthermore, we want to do as much of the number crunching as possible on the C++ side for speed reasons. If we express this code as a directed acyclic graph, we end up with something like this:
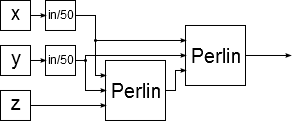
The idea of expressing calculations as node systems is not new; Blender, for example, uses them as well. For a more sophisticated example, consider this code fragment:
float pX = x/50.0;
float pY = y/50.0;
float pZ = z/50.0;
float result = 0;
for (int i = 0; i < 5; i++)
{
result += pow(2,-i)*perlin(pow(2,i)*pX,pow(2,i)*pY,pow(2,i)*pZ);
}This is a basic fractalization of our perlin noise. On a graph level, with a dedicated fractalization node, it looks like this:
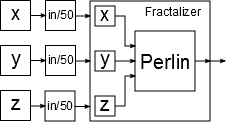
This network approach sounds very good on paper, but it raises a few questions:
- What kind of data types do we use?
- How do we efficiently(!) evaluate the network?
- How do we express arbitrary arithmetic expressions?
Our first approach tried to solve these problems as follows: We determined that most data types these expressions should be capable of handling are floating point values and floating point vectors. So our internal network representation revolved around an abstract node class Node
- Evaluating a node results in a virtual function call, which is slow.
- Function nodes also had to keep track of their input types. The simple solution we used at this point was to add a templated input type to the already templated output type. However, this had the side-effect that each function node could only accept one type of input, so a function taking three scalar values was possible, but not one taking a vector and a scalar value. (For template experts: Variadic templates might have solved this problem, but would not have helped with the maintainability of the code. The whole template system quickly became a mess anyways, and slowed compiling down by quite a bit.)
- Caching the results led to more member variables, and the overhead of checking if a node had already been evaluated, and the overhead of resetting all the cached values after each evaluation. This could have been resolved via topological sorting.
- The system could not have been used from multiple threads, since the caching would have to be done thread-locally.
Each of these reasons could probably have been dealt with, but the final nail in the coffin was this last one:
- The type system did not support infinitely many types.
Since templates need to be instantiated at compile time, each possible type must be known at compile time, and there needs to be code generated for each instantiation. However, we came up with a feature we did not quite anticipate in the beginning. We wanted to be able to derive the node networks (as in calculating the analytical derivative), and obtain a new node network again. However, finding the derivative of an expression that returns a vector with respect to another vector leads to matrices in the calculation of the derivative (more on the math behind that in a future article). That is, if we take an expression, and derive it n times, we can end up with an result type of order n. This leads to an infinite amount of possible result types (as we can derive an expression as often as we want to). However, this clashes with the concept of templates. Faced with these problems, we redesigned the Node Network system.
- Types are now basically vectors of ints. Derivation of matrices leads to "three-dimensional" matrices, which we will call tensors here (mind that a tensor in physics appears to be a bit different to our definition), and deriving a tensor leads to a higher-order tensor. Our types state the dimensions of the tensor. So [1] would be a scalar value, [4] a vec4, [2,2] a mat2, and [2,5,4] a tensor of order 3 with the dimensions 2, 5 and 4 (also representable as a 2x5 matrix containing vec4s instead of scalar values).
- Evaluation is done by converting the network into linearized byte code. We generate assembly-like instructions, and execute them with an interpreter. This has the added benefit that scalar operations on the tensor structure are compiled to pure scalar operations; that is, there is no overhead for managing a tensor if we are just evaluating scalar expressions. In terms of programming paradigms, we shifted from object-oriented programming to data-oriented design.
- The expression system was kept, but without the templates.
These points will all be explained in-depth in the next two articles, "Expressions" and "Bytecode".